Leute,
Bei der Verfolgung der Wahlen im letzten Herbst hörten wir oft, dass eine bestimmte Umfrage entweder richtig oder falsch war statistisch signifikant. Ein Beispiel: Kandidat A lag in einer Umfrage mit 1.000 Personen mit 51 zu 49 % vor Kandidat B. Die Ergebnisse waren jedoch statistisch nicht signifikant, da die Fehlerspanne (MOE) lag bei etwas mehr als 3 %. Beispiele wie dieses verleihen der statistischen Signifikanz zu Recht ein Gefühl der Wichtigkeit. Bei sehr großen Stichprobenumfängen kann diese Bedeutung jedoch irreführend sein. Ich habe über dieses Thema schon einmal gebloggt, aber es lohnt sich, es zu wiederholen, insbesondere mit einem quantitativen Beispiel.
Für dieses Beispiel wollen wir uns einige Daten aus der SMT-Industrie ansehen. Angenommen, ein Ingenieur möchte 3 Lötpasten auf ihre Leistung hin bewerten für Transfereffizienz (TE). Der Zielwert ist 100%. Paste 1 hat einen TE von 98 %, Paste 2 einen TE von 97 % und Paste 3 einen TE von 86 %. Die Daten aller Pasten weisen eine Standardabweichung von 20 % auf. Leider hat ihr Unternehmen noch kein modernes Gerät angeschafft. SPI (Lotpasteninspektion) Da sie kein Volumenmessgerät besitzt, muss sie alle Lotpastendepots mit einem Mikroskop messen. Sie misst also nur zwanzig Proben für jede Paste. Mit den oben genannten Daten und jeweils 20 Proben kann sie einige statistische Berechnungen durchführen und mit 95 %iger Sicherheit zeigen, dass es keinen statistisch signifikanten Unterschied in der TE zwischen den Pasten 1 und 2 gibt, dass aber beide Pasten der Paste 3 überlegen sind.
Einen Monat später kauft ihr Unternehmen jedoch ein SPI-Gerät. Es kann Lotpastenablagerungen so schnell scannen, dass sie 20.000 Ablagerungen für jede der drei Pasten scannt. Es ist beruhigend, dass das SPI genau die gleichen Ergebnisse liefert, d. h. Paste 1 hat einen TE von 98 %, Paste 2 einen TE von 97 % und Paste 3 einen TE von 86 %. Alle Pasten weisen immer noch eine Standardabweichung von 20 % auf.
Wir haben also die gleichen Ergebnisse, richtig? Nun, nein. Natürlich sind die Pasten 1 und 2 immer noch besser als Paste 3, aber in diesem Fall ist Paste 1 nun statistisch gesehen besser als Paste 2. Selbst wenn Paste 2 mit einem TE von 97,67 % einträfe, wäre Paste 1 mit 95-prozentiger Sicherheit statistisch besser als Paste 2.
Wie kommt es zu dieser Veränderung? Sie hängt mit dem Stichprobenumfang zusammen. Das 95%-Konfidenzintervall des Mittelwerts (CIM) wird zum Teil durch die Standardabweichung geteilt durch die Quadratwurzel des Stichprobenumfangs bestimmt. Dieser Term wird als die Standardfehler des Mittelwerts (SEM).
Mit zunehmender Stichprobengröße wird der SEM kleiner. Abbildung 1 zeigt einen Vergleich der Stichprobenverteilungen der Mittelwerte für Paste 1 und 2, wenn der Stichprobenumfang 20 beträgt; Abbildung 2 zeigt ihn, wenn der Stichprobenumfang 20.000 beträgt. Die Konfidenzintervalle des Mittelwerts für jede Verteilung sind durch Linien mit Pfeilspitzen dargestellt. In Abbildung 1 ist zu erkennen, dass sich die CIMs bei einem Stichprobenumfang von 20 stark überschneiden, was darauf hindeutet, dass es keinen statistischen Unterschied gibt. In Abbildung 2 hingegen liegen die CIMs weit auseinander, was darauf hindeutet, dass sich diese beiden Verteilungen statistisch stark unterscheiden.
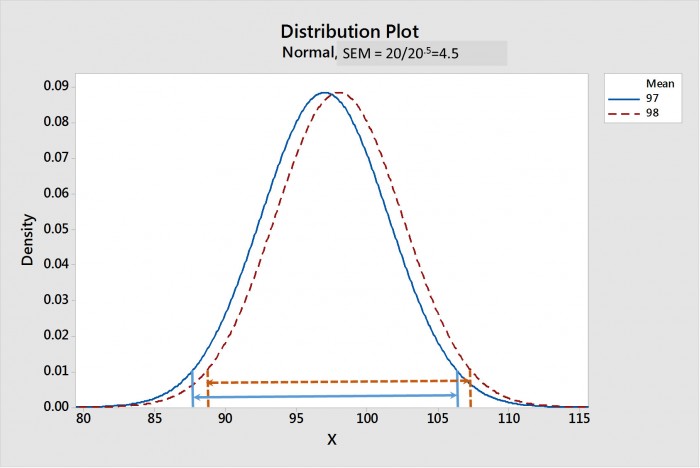
Abbildung 1. Die Stichprobenverteilung der Mittelwerte für die Proben 1 und 2 mit einem Stichprobenumfang von 20. Die 95%-Konfidenzintervalle der Mittelwerte (CIMs) sind durch die gepfeilten Linien dargestellt. Man beachte, dass sich die CIMs überschneiden, was auf einen statistischen Unterschied hindeutet.

Abbildung 2. Die Stichprobenverteilung der Mittelwerte für die Pasten 1 und 2 bei einem Stichprobenumfang von 20.000. Die 95%-Konfidenzintervalle der Mittelwerte (CIMs) sind durch die gepfeilten Linien dargestellt. Man beachte, dass sich die CIMs nicht überschneiden, was auf einen starken statistischen Unterschied hindeutet.
Was bedeutet diese Situation für uns?
Wenn eine Stichprobengröße von 20.000 es uns erlaubt zu sagen, dass ein statistisch signifikanter Unterschied zwischen einer durchschnittlichen TE von 98% und einer von 97,67% besteht, müssen wir natürlich ihren Wert in Frage stellen. Nehmen wir als Beispiel an, dass das Management entschieden hat, dass TE der kritischste Parameter beim Kauf einer Lötpaste ist. Nehmen wir weiter an, dass Paste 1 einen TE-Wert von 98 % hat und Paste 2 einen statistisch unterschiedlichen TE-Wert von 97,67 %. Allerdings reagiert Paste 1 sehr schlecht auf Pausen. Nehmen wir außerdem an, dass alle anderen Leistungskennzahlen gleich sind. In diesem Fall würde ich argumentieren, dass sich die TEs der Pasten 1 und 2 nicht "praktisch signifikant" unterscheiden und als gleichwertig betrachtet werden sollten. Wenn man die überlegene Reaktion auf die Pause von Paste 2 hinzufügt, sollte sie der Gewinner sein.
Wie wird die "praktische Bedeutung" bestimmt? Das wird von Fall zu Fall unterschiedlich sein, aber ich würde behaupten, dass bei TE ein Unterschied im Bereich von 2 bis 5 % praktisch nicht signifikant ist. In den meisten Fällen sollte die "praktische Bedeutung" durch Experimente ermittelt werden. Mit modernen Werkzeugen wie SPI-Geräten, die Tausende von Datenpunkten messen können, sehe ich jedoch die Notwendigkeit, die Dichotomie von statistischer und praktischer Bedeutung zu verstehen, immer häufiger.
Diese Situation wurde mir noch klarer, als ich vor kurzem einige TE-Daten mit Stichprobengrößen von über 20.000 analysierte.
Zum Wohl,
Dr. Ron
