朋友們
在關注去年秋天的選舉時,我們經常聽到某項民意調查是或不是 有統計意義.舉例來說,候選人 A 在 1,000 人的民調中以 51% 對 49% 領先候選人 B,但結果在統計學上並不顯著,因為 誤差範圍 是 3% 多一點。像這樣的例子當之無愧地讓統計顯著性有了重要的意義。然而,在樣本量非常大的情況下,這種顯著性可能會產生誤導。我之前在部落格中討論過這個主題,但還是值得重複一次,尤其是以量化的例子來說。
在這個範例中,讓我們來看看 SMT 產業的一些資料。假設一位工程師想要評估 3 種焊膏在以下方面的效能 傳輸效率 (TE).目標值為 100%。漿料 1 的 TE 值為 98%,漿料 2 的 TE 值為 97%,漿料 3 的 TE 值為 86%。所有漿料的數據的標準偏差為 20%。不幸的是,她的公司還沒有購買現代化的 SPI (焊膏檢測) 因此,她必須使用顯微鏡測量所有焊膏的沉積量。因此,她只測量每種焊膏的 20 個樣本。有了上述數據和各 20 個樣品,她就可以執行一些統計計算,並以 95% 的置信度顯示焊膏 1 和焊膏 2 之間在 TE 方面沒有統計上的顯著差異,但兩種焊膏都比焊膏 3 優勝。
然而,一個月後,她的公司購買了一台 SPI 工具。它可以快速掃描焊膏沉積物,她為 3 種焊膏中的每一種掃描了 20,000 個沉積物。令人欣慰的是,SPI 產生了完全相同的結果,即焊膏 1 的 TE 為 98%,焊膏 2 的 TE 為 97%,而焊膏 3 的 TE 相當於 86%。所有貼片仍顯示出 20% 的標準偏差。
所以,我們的結果是一樣的吧?當然不是。當然,漿糊 1 和 2 仍然勝過漿糊 3,但是,在這種情況下,漿糊 1 現在在統計學上優於漿糊 2。事實上,即使貼片2的TE值為97.67%,貼片1在統計學上仍優於貼片2,置信度為95%。
是什麼導致這種變化?這與樣本數量有關。 平均值的95%置信區間(CIM) 部分由標準差除以樣本數的平方根決定。此項稱為 平均值的標準誤差 (SEM).
隨著樣本數量增加,SEM 也會變小。圖 1 顯示了 平均值的抽樣分佈 當樣本數為 20 時,圖一和圖二為貼圖 1 和貼圖 2;當樣本數為 20,000 時,圖二為貼圖 1 和貼圖 2。每個分佈的平均值置信區間以箭頭線表示。請注意,在圖 1 中,當樣本數量為 20 時,CIMs 強烈重疊,顯示沒有統計差異。而在圖 2 中,CIMs 分離得很開,顯示這兩個分佈在統計學上有很大的差異。
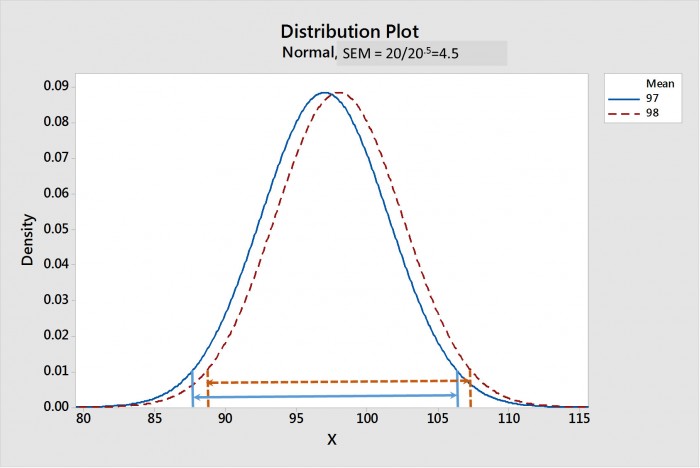
圖 1.樣本數為 20 的試料 1 和試料 2 平均值的抽樣分佈。箭頭線表示平均值的 95% 置信區間 (CIM)。請注意 CIMs 重疊,顯示統計上的差異。

圖 2.樣本量為 20,000 份的試料 1 和試料 2 平均值的抽樣分佈。平均值的 95% 置信區間 (CIM) 由箭頭線表示。請注意 CIMs 並無重疊,顯示出強烈的統計差異。
這種情況讓我們何去何從?
很明顯,如果 20,000 個樣本讓我們可以說平均 TE 值 98% 和 97.67% 之間有統計上的顯著差異,我們就必須質疑它的價值。舉例來說,假設管理階層決定 TE 是採購焊膏時最關鍵的參數。我們也假設焊膏 1 有 98% 的 TE,而焊膏 2 有統計上不同的 97.67% TE。但是,焊膏 1 對暫停的反應非常差。我們也假設所有其他效能指標都相同。在這種情況下,我認為貼片 1 和貼片 2 的 TE 沒有「實際上的顯著」差異,應該被視為相同。加上漿料 2 對暫停的優異反應性能,它應該是贏家。
如何決定「實際重要性」?這會因個案而異,但我認為,對於 TE 來說,2% 到 5%範圍內的差異實際上並不重要。在大多數情況下,工程師應該透過一些實驗來判斷「實際重要性」。然而,有了 SPI 裝置等現代工具,可以量測成千上萬的資料點,我可以看到了解統計與實際差異二分法的需求變得越來越普遍。
最近我分析了一些樣本量超過 20,000 個的 TE 資料,讓我更真實地感受到這種情況。
乾杯
羅恩博士
