皆さん、
昨秋の選挙を追っていると、ある世論調査が当たったとか当たらないとかいう話をよく耳にした。 統計的に有意.例として、1,000人規模の世論調査で候補者Aが候補者Bを51対49%でリードしたが、結果は統計的に有意ではなかった。 誤差の範囲 は3%強だった。このような例は、統計的有意性を重要視して当然である。しかし、サンプルサイズが非常に大きい場合、この有意性は誤解を招く可能性がある。このトピックについては以前にもブログに書いたことがあるが、特に定量的な例を用いて、繰り返し説明する必要がある。
この例では、SMT業界のデータを見てみましょう。あるエンジニアが3つのソルダーペーストの性能を評価したいとします。 転送効率 (TE)である。目標値は100%。ペースト1のTEは98%、ペースト2のTEは97%、ペースト3のTEは86%である。すべてのペーストの標準偏差は20%である。残念ながら、彼女の会社ではまだ最新の SPI(ソルダーペースト検査) このため、彼女はすべてのソルダーペーストの付着量を顕微鏡で測定しなければならない。そのため、彼女は各ペーストについて20サンプルしか測定しない。上記のデータと20個のサンプルを使って統計計算を行い、信頼度95%で、ペースト1と2の間にTEに統計的に有意な差はないが、どちらのペーストもペースト3より優れていることを示すことができます。
しかし1ヵ月後、彼女の会社はSPIツールを購入した。SPIはソルダーペーストの付着物を高速でスキャンできるため、彼女は3つのペーストそれぞれについて20,000個の付着物をスキャンした。すなわち、ペースト1のTEは98%、ペースト2のTEは97%、ペースト3のTEは86%であった。すべてのペーストが20%の標準偏差を示している。
では、結果は同じか?いや、違う。もちろん、ペースト1と2はペースト3に勝っているが、この場合、ペースト1はペースト2より統計的に優れている。実のところ、仮にペースト2のTEが97.67%だったとしても、95%の信頼度でペースト1がペースト2より統計的に優れていることになる。
この変化の原因は?それは標本サイズに関係している。 平均の95%信頼区間(CIM)は、標準偏差を標本サイズの平方根で割った値で決定されます。この項は 平均の標準誤差 (SEM)。
サンプルサイズが大きくなると、SEMは小さくなる。図1は 平均値の標本分布 図2は,標本サイズが20,000の場合である。各分布の平均の信頼区間は、矢印の付いた線で示されている。図1では、サンプルサイズが20の場合、CIMが強く重なっており、統計的な差がないことを示唆していることに注意してください。一方、図2では、CIMは大きく離れており、この2つの分布が統計的に強く異なることを示唆している。
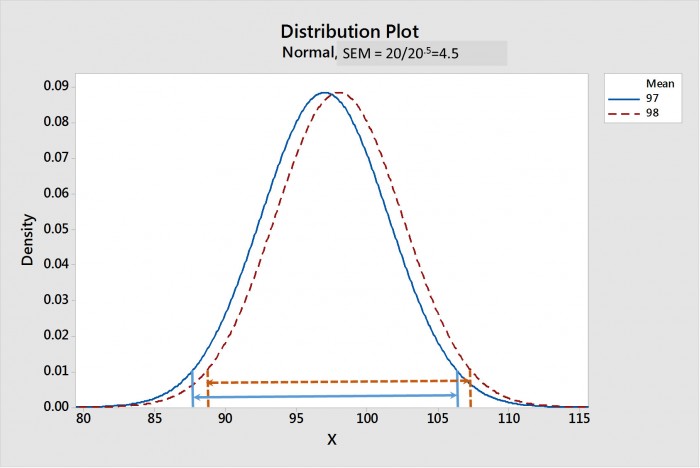
図1.サンプル・サイズ20の場合の平均のサンプリング分布。平均値の95%信頼区間(CIM)を矢印の線で示す。CIMsが重なり合っていることに注意。

図2.サンプル・サイズ20,000の場合の平均のサンプリング分布。平均値の95%信頼区間(CIM)を矢印の線で示す。CIMsが重なっていないことに注意してください。
この状況をどう考えるか?
サンプル数が20,000で、平均TEが98%の場合と97.67%の場合で統計的に有意な差があると言えるのであれば、その価値を疑問視せざるを得ないのは明らかである。例として、経営陣がソルダーペーストの購入においてTEが最も重要なパラメータであると判断したとします。また、ペースト1のTEが98%で、ペースト2のTEが統計的に異なる97.67%であったとします。しかし、ペースト1は一時停止に対する反応が非常に悪い。また、他のすべての性能指標が同じであるとします。この場合、ペースト1と2のTEは「実質的に有意な」差はなく、同じと考えるべきだと私は主張する。ペースト2の一時停止に対する優れた反応性能を加えれば、ペースト2が勝者となるはずだ。
実質的な有意性」はどのように決まるのですか?ケースバイケースですが、私はTEでは2~5%の差は実用上重要ではないと考えます。ほとんどの場合、エンジニアリングはいくつかの実験によって「実用的な有意性」を判断すべきです。しかし、SPIデバイスのような何千ものデータポイントを測定できる最新のツールでは、統計的有意差と実用的有意差の二分法を理解する必要性がますます一般的になってきていると思います。
つい最近、サンプル数が2万を超えるTEデータを分析したところ、この状況がより現実味を帯びてきた。
乾杯
ロン博士
